




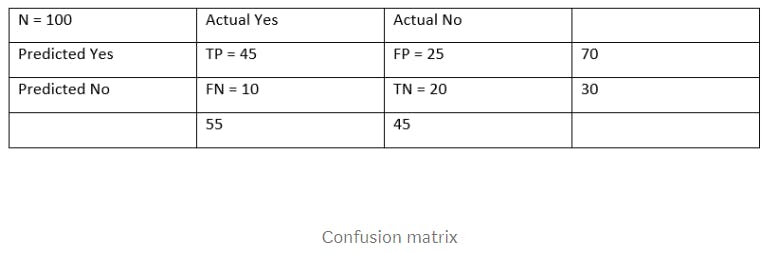
Confusion Matrix: is a table that is used describe the performance of classification model.
For example our classification model made 100 prediction on whether person has a disease or not.
- Out of 100 prediction, model predicted 70 times yes and 30 times no.
- In Actual result, 55 have a disease and 45 have not a disease.
Let’s build confusion matrix, but first get basic terms for confusion matrix:
True Positive(TP): Actual label is yes and model also predict yes.
True Negative(TN): Actual label is No and model predict No.
False Positive(FP): Actual label is No and model predict Yes. This is called Type I error.
False Negative(FN): Actual label is Yes and model predict No. This is called Type II error.
The list of metrics that can be calculated from confusion matrix:
- Accuracy: (TP + TN)/total = (45 + 20)/100 = 6.5
- Misclassification Rate: (FP + FN)/total = (25 + 10)/100 = 3.5 Or (1- Accuracy) = 0.35
- True Positive Rate: TP/actual_yes = 45/55
- True Negative Rate: TN/actual_no = 20/45
- False Positive Rate: FP/actual no = 10/45
- False Negative Rate: FN/actual_yes = 24/70
- Precision : TP/total predicted_yes = 45/70
- Recall: TP/total actual_yes
- Prevalence: actual_yes/total = 55/100
Other metrics can be useful for classification model:
- Null error rate: how many wrong prediction will be there if you predict only majority class like if you predict only yes in above example then null error rate will be 45/100. This can be baseline metric to compare against our classifier.
- F1 Score: harmonic mean of precision and recall.
- ROC curve: plot between True positive rate and False positive rate. Cohen’s Kappa
- Important point for newcomers: Accuracy metric is always not a good metric for predictive models because if one class is dominating 99% times then accuracy of model will be 99% if we predict only one class. Precision and recall are better metrics in such cases, but precision too can be biased by very unbiased class. Keep learning and be innovative.