




Textual Data that is being generated by speaking, tweeting, and messaging is huge but problem with this is that it is high unstructured.
For example when we chat with our friend we use some local word which don’t have proper meaning in dictionary.
We can get significant insight from text data using techniques and principles of Natural Language Processing (NLP).
- Introduction to NLP
NLP is a part of Data Science. By utilizing NLP, we can organize the massive amount of text data and perform numerous automated tasks such as automatic summarization, machine translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition and topic segmentation etc.
- Text Preprocessing
Since, Text is unstructured data, which contain various type of noise. To make it ready for analysis we have perform text preprocessing like noise removal, lexicon Normalization and object Standardization. For example, social media data is highly unstructured data, it is an informal communication which uses bad grammar, slang words etc.
2.1 Noise Removal
any piece of text which is not relevant to the context of the data. For example: language stopwords (like is, am, the), punctuation, URLs and industry specific words.
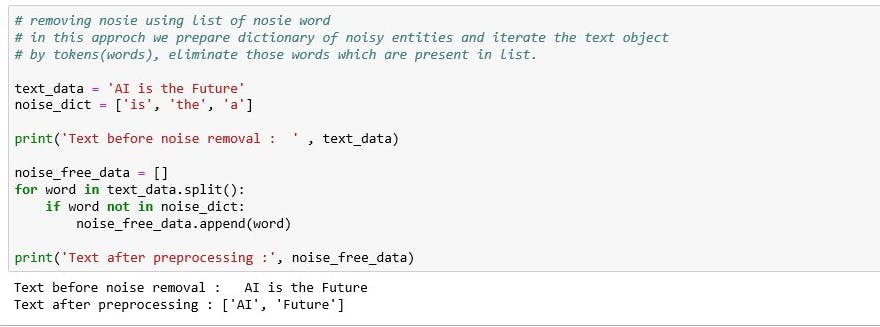 Text preprocessing using list
Text preprocessing using list
2.2 Lexicon Normalization
is a another type of textual noise, in which one word exhibited multiple representation. For example “play”, “player”, “played” and “playing” are different variation of the word “play”. Though they mean different but contextually all are similar. The most common lexicon normalization practices are:
- Stemming: is a basic rule based process of stripping the suffixes like “ing”, “ly”, “s”, “es” etc from a word.
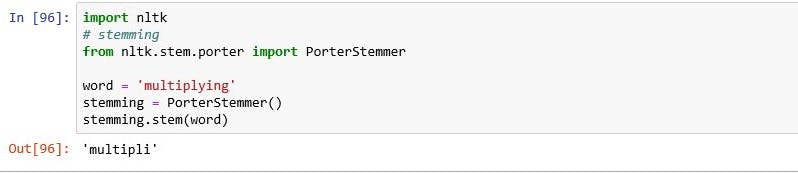 Stemming
Stemming
- Lemmatization: is an organized and step by step process of obtaining the root form of the word, it make use of vocabulary and morphological analysis(word structure and grammar relations).
 Lemmatization
Lemmatization
- Object Standardization: text data contain word or phrases which are not present in any lexical(vocabulary of a language) dictionaries. Such as acronyms, hashtags and slangs. With the help of regular expression and prepare dictionary we can noise these type of noise.
 Object Standardization
Object Standardization
Other type of text preprocessing include encoding-decoding noise, grammar checker and spelling correction(algorithms like Levenshtein Distance and Dictionary lookup).
- Text to features(Feature Engineering on text data)
To analyze a preprocessed data, it need to be converted into features by following techniques syntactical parsing, entities/N-grams/ word-based features, statistical features and word embedding.
3.1 Syntactic parsing
It involves the analysis of words in the sentence for grammar and their relationships among the words. Dependency Grammar and part of speech tags are the import attribute of text syntactic.
Dependency Grammar:- deals with binary relations between two lexical items. Every relation can be represented in the form of relation, governor, dependent. It form tree like structure, when you parsed recursively in top-down manner gives grammar relation output which can be used as features for many NLP problems like entity wise sentiment analysis, text classification etc.
Part of speech tagging: Every word in a sentence is associated with a part of speech(pos) tag(nouns, verbs, adjectives etc)
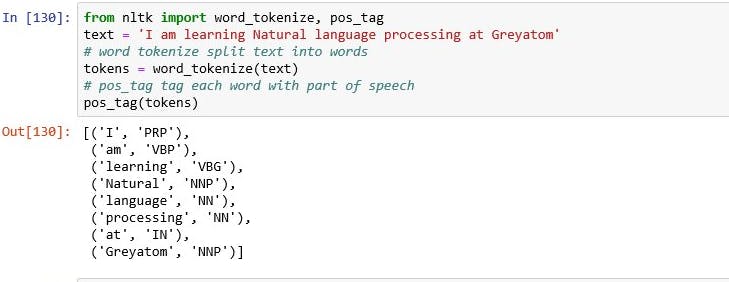 pos_tag
pos_tag
Pos is used for many important purposes in NLP:
Word Sense disambiguation: some word have multiple meaning according to their usage for example 1. “please book my flight”, 2.“I’am reading this book”, in first sentence book is verb while in second sentence book is noun.
Improving word-based features: A learning model could learn different context of a word when used word as the features with part of speech is linked with them, the context is preserved, thus making strong features.
Normalization and Lemmatization: pos tags are the basis of lemmatization process for converting a word to its base form(lemma).
Stopword removal: pos tags are also useful in efficient removal of stopwords.
3.2 Entity extraction
Entities are parts of sentence like noun phrases, verb phrases or both. Entity detection algorithm are group of rule based parsing, dictionary lookups, pos tagging and dependency parsing. the application of this is in the automated chat bots, content analyzers and consumer insights.
Types of entity detection method are Topic modelling and Named Enity Recognition.
Named Entity Recognition(NER): is a process of detecting the named entities such as person name, location names, company name etc. from the text. A NER model consist of three blocks: 1. Noun phrase identification(deals with extracting all the noun phrases from text using dependency parsing and part of speech tagging). 2. Phrase classification(extracted phrase are classified into respective categories like name, location etc.). 3. Entity disambiguation(using knowledge graph like google knowledge graph, IBM watson to validate classified entities).
Topic Modeling: is a process of automatically identifying the topics present in the text documents.
3.3 Statistical Features
Text data can be converted into number using various technique like:
- Term Frequency-Inverse Document frequency(TF-IDF): It convert test documents into vector model on the basis of occurrence of words in documents without considering the exact order.
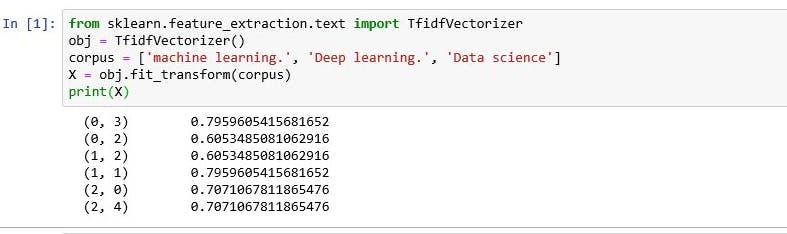
3.4 Word Embedding(text vectors)
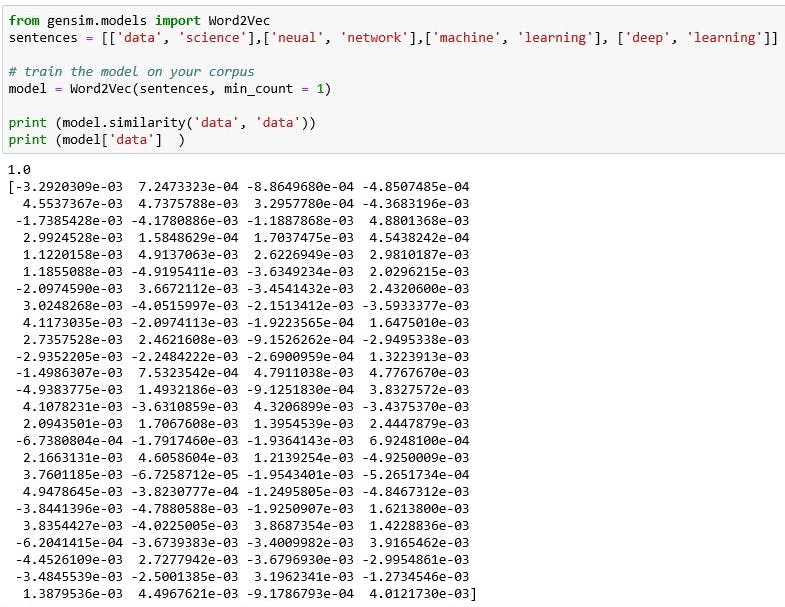
Word Embedding is the modern way of representing words as vectors. The aim of word embedding is to redefine the high dimensional word features into low dimension feature vectors by preserving the contextual similarity in documents. Word2Vec and GloVe are two popular model to create word embedding of a text. These vector can be used as feature vectors for ML model and used to measure text similarity using cosine similarity, word clustering and text classification technique.
- Use cases of NLP
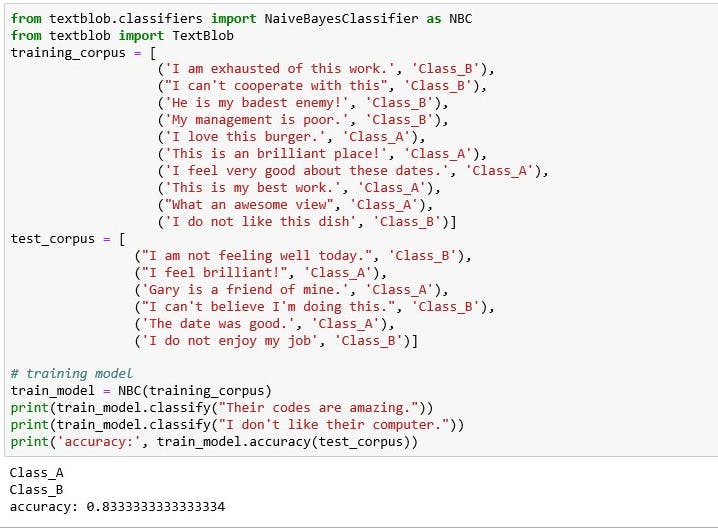
- Text Classification: is defined as a technique to systematically classify a text object(document or sentence) in one of the fixed category. For example like email spam identification, topic classification of news, sentiment classification and organization of web pages by search engine.
- Co-reference Resolution:
is a process of finding relation among the words within sentence. For example: “ Roshan buy a new car. He derived it continuously for three hour.” Coreference resolution can find that “he” denote Roshan and “it” denote car.